
lhc的博客网站
正则表达式(Regular Expression,简称 Regex 或 RegExp)是一种用来匹配字符串中字符组合的模式。
正则表达式是一种用于模式匹配和搜索文本的工具。
正则表达式提供了一种灵活且强大的方式来查找、替换、验证和提取文本数据。
正则表达式可以应用于各种编程语言和文本处理工具中,如 JavaScript、Python、Java、Perl 等。
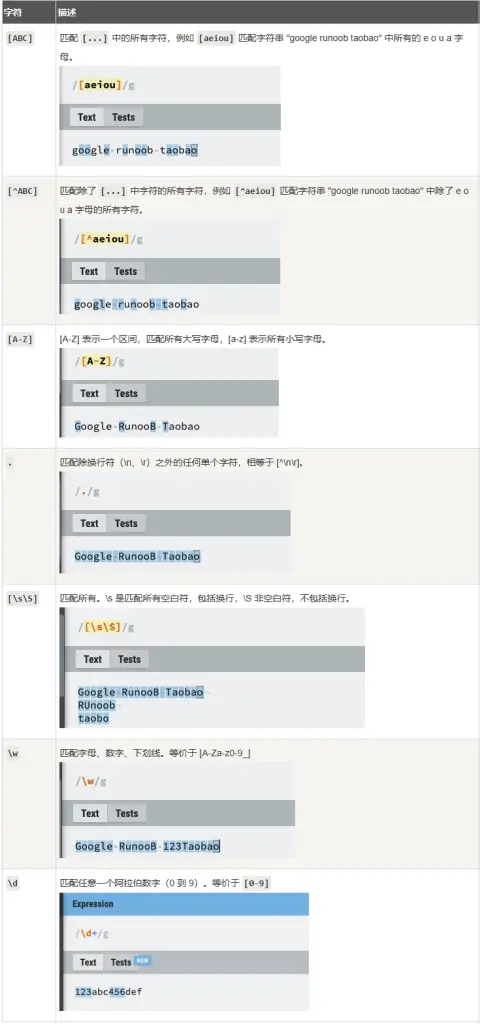
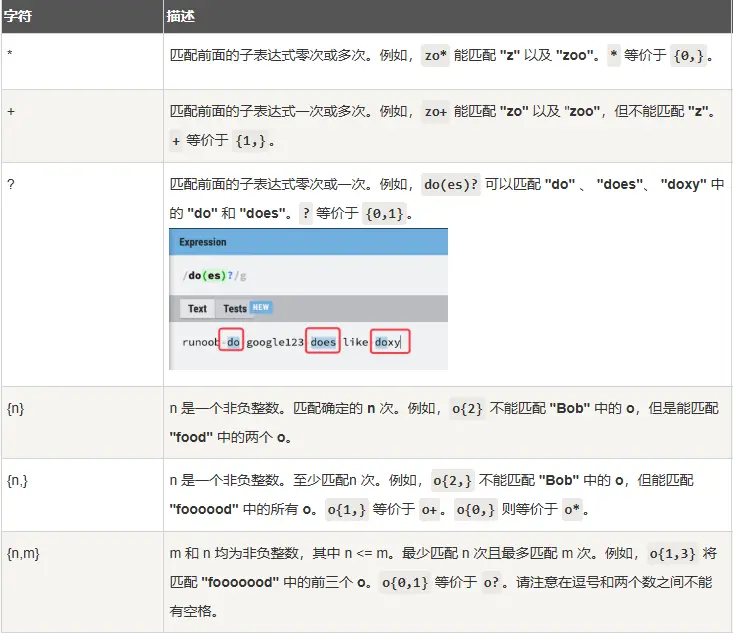
\d 匹配任意数字字符,\w 匹配任意字母数字字符,. 匹配任意字符(除了换行符)等。*:匹配前面的模式零次或多次。+:匹配前面的模式一次或多次。?:匹配前面的模式零次或一次。{n}:匹配前面的模式恰好 n 次。{n,}:匹配前面的模式至少 n 次。{n,m}:匹配前面的模式至少 n 次且不超过 m 次。[ ]:匹配括号内的任意一个字符。例如,[abc] 匹配字符 “a”、”b” 或 “c”。[^ ]:匹配除了括号内的字符以外的任意一个字符。例如,[^abc] 匹配除了字符 “a”、”b” 或 “c” 以外的任意字符。^:匹配字符串的开头。$:匹配字符串的结尾。\b:匹配单词边界。\B:匹配非单词边界。( ):用于分组和捕获子表达式。(?: ):用于分组但不捕获子表达式。\:转义字符,用于匹配特殊字符本身。.:匹配任意字符(除了换行符)。|:用于指定多个模式的选择。 所谓特殊字符,就是一些有特殊含义的字符,如上面说的 runoo*b 中的 *,简单的说就是表示任何字符串的意思。如果要查找字符串中的 * 符号,则需要对 * 进行转义,即在其前加一个 \,runo\*ob 匹配字符串 runo*ob。
许多元字符要求在试图匹配它们时特别对待。若要匹配这些特殊字符,必须首先使字符”转义”,即,将反斜杠字符\ 放在它们前面。
限定符用来指定正则表达式的一个给定组件必须要出现多少次才能满足匹配。有 * 或 + 或 ? 或 {n} 或 {n,} 或 {n,m} 共6种。
* 和 + 限定符都是贪婪的,因为它们会尽可能多的匹配文字,只有在它们的后面加上一个 ? 就可以实现非贪婪或最小匹配。
定位符使您能够将正则表达式固定到行首或行尾。它们还使您能够创建这样的正则表达式,这些正则表达式出现在一个单词内、在一个单词的开头或者一个单词的结尾。
定位符用来描述字符串或单词的边界,^ 和 $ 分别指字符串的开始与结束,\b 描述单词的前或后边界,\B 表示非单词边界。
用圆括号 () 将所有选择项括起来,相邻的选择项之间用 | 分隔。
() 表示捕获分组,() 会把每个分组里的匹配的值保存起来, 多个匹配值可以通过数字 n 来查看(n 是一个数字,表示第 n 个捕获组的内容)。
对一个正则表达式模式或部分模式两边添加圆括号将导致相关匹配存储到一个临时缓冲区中,所捕获的每个子匹配都按照在正则表达式模式中从左到右出现的顺序存储。缓冲区编号从 1 开始,最多可存储 99 个捕获的子表达式。每个缓冲区都可以使用 \n 访问,其中 n 为一个标识特定缓冲区的一位或两位十进制数。
可以使用非捕获元字符 ?:、?= 或 ?! 来重写捕获,忽略对相关匹配的保存。