修饰符(标记)
正则表达式修饰符(也称为模式修饰符或标记)是用于改变正则表达式匹配行为的特殊指令。
标记也称为修饰符,正则表达式的标记用于指定额外的匹配策略。
标记不写在正则表达式里,标记位于表达式之外,格式如下:
/pattern/flags
常用修饰符
-
1.
i(ignore case) – 忽略大小写- 使匹配不区分大小写
- 示例:
/abc/i可以匹配 “abc”, “Abc”, “ABC” 等 - 支持语言:几乎所有正则表达式实现(JavaScript、PHP、Python等)
2.
g(global) – 全局匹配- 查找所有匹配项,而不是在第一个匹配后停止
- 示例:在字符串 “ababab” 中,
/ab/g会匹配所有三个 “ab” - 支持语言:JavaScript、PHP等
3.
m(multiline) – 多行模式- 改变
^和$的行为,使其匹配每行的开头和结尾,而不仅是整个字符串的开头和结尾 - 示例:在多行字符串中,
/^abc/m会匹配每行开头的 “abc” - 支持语言:JavaScript、PHP、Python、Perl等
4.
s(single line/dotall) – 单行模式- 使点号
.匹配包括换行符在内的所有字符 - 在JavaScript中称为”dotall”模式,使用
/s修饰符 - 示例:
/a.b/s可以匹配 “a\nb” - 支持语言:PHP、Perl、Python(作为
re.DOTALL)、JavaScript(ES2018+)
5.
u(unicode) – Unicode模式- 启用完整的Unicode支持
- 正确处理UTF-16代理对和Unicode字符属性
- 示例:
/\p{Script=Greek}/u可以匹配希腊字母 - 支持语言:JavaScript、PHP等
6.
y(sticky) – 粘性匹配- 从目标字符串的当前位置开始匹配(使用
lastIndex属性) - 类似于
^锚点,但针对的是匹配的起始位置 - 示例:在JavaScript中,
/a/y会从lastIndex开始匹配 “a” - 支持语言:JavaScript
7.
x(extended) – 扩展模式- 忽略模式中的空白和注释,使正则表达式更易读
- 示例:在PHP中,
/a b c/x等同于/abc/ - 支持语言:PHP、Perl、Python(作为
re.VERBOSE)
元字符
正则表达式中的元字符是具有特殊含义的字符,它们不表示字面意义,而是用于控制匹配模式。
基本元字符
.(点号)匹配除换行符(
\n)外的任意单个字符示例:
a.b匹配 “aab”, “a1b”, “a b” 等
^(脱字符)匹配字符串的开始位置
示例:
^abc匹配以 “abc” 开头的字符串
$(美元符)匹配字符串的结束位置
示例:
xyz$匹配以 “xyz” 结尾的字符串
\(反斜杠)转义字符,使后面的字符失去特殊含义
示例:
\.匹配实际的点号而不是任意字符
字符类元字符
[](方括号)定义字符集合,匹配其中任意一个字符
示例:
[aeiou]匹配任意一个元音字母
[^](否定字符类)匹配不在方括号中的任意字符
示例:
[^0-9]匹配任意非数字字符
-(连字符)在字符类中表示范围
示例:
[a-z]匹配任意小写字母
量词元字符
*(星号)匹配前面的子表达式零次或多次
示例:
ab*c匹配 “ac”, “abc”, “abbc” 等
+(加号)匹配前面的子表达式一次或多次
示例:
ab+c匹配 “abc”, “abbc” 但不匹配 “ac”
?(问号)匹配前面的子表达式零次或一次
示例:
colou?r匹配 “color” 和 “colour”
{n}(花括号)精确匹配n次
示例:
a{3}匹配 “aaa”
{n,}至少匹配n次
示例:
a{2,}匹配 “aa”, “aaa” 等
{n,m}匹配n到m次
示例:
a{2,4}匹配 “aa”, “aaa”, “aaaa”
分组和选择元字符
()(圆括号)定义子表达式或捕获组
示例:
(ab)+匹配 “ab”, “abab” 等
|(竖线)表示”或”关系
示例:
cat|dog匹配 “cat” 或 “dog”
特殊字符类元字符
\d匹配任意数字,等价于
[0-9]
\D匹配任意非数字,等价于
[^0-9]
\w匹配任意单词字符(字母、数字、下划线),等价于
[a-zA-Z0-9_]
\W匹配任意非单词字符,等价于
[^a-zA-Z0-9_]
\s匹配任意空白字符(空格、制表符、换行符等)
\S匹配任意非空白字符
边界匹配元字符
\b匹配单词边界
示例:
\bcat\b匹配 “cat” 但不匹配 “category”
\B匹配非单词边界
示例:
\Bcat\B匹配 “scattered” 中的 “cat” 但不匹配单独的 “cat”
其他元字符
\n匹配换行符
\t匹配制表符
\r匹配回车符
\f匹配换页符
\v匹配垂直制表符
贪婪与非贪婪量词
默认情况下,量词(
*,+,?,{})是贪婪的,会尽可能多地匹配字符。在量词后加?可使其变为非贪婪(懒惰)模式:*?:零次或多次,但尽可能少+?:一次或多次,但尽可能少??:零次或一次,但尽可能少{n,m}?:n到m次,但尽可能少
示例:
<.*?>匹配HTML标签时不会跨标签匹配
正向和负向预查
(?=...)(正向肯定预查)匹配后面跟着特定模式的位置
示例:
Windows(?=95|98)匹配后面跟着95或98的”Windows”
(?!...)(正向否定预查)匹配后面不跟着特定模式的位置
示例:
Windows(?!95|98)匹配后面不跟着95或98的”Windows”
(?<=...)(反向肯定预查)匹配前面是特定模式的位置
示例:
(?<=95|98)Windows匹配前面是95或98的”Windows”
(?<!...)(反向否定预查)匹配前面不是特定模式的位置
示例:
(?<!95|98)Windows匹配前面不是95或98的”Windows”
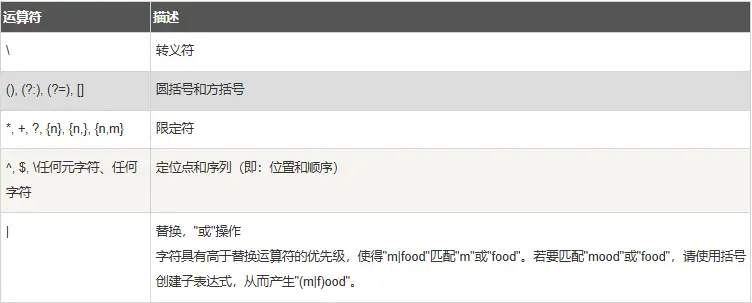
运算符优先级